Resolving the Frontend/Backend API Design Conflict
As part of my API design consulting engagements, I’m often called in to resolve the conflict between the API design that the frontend developers would prefer to have and the backend developers want to build. These conflicts can often be a serious distraction and over time can build into bigger issues within the team.
So, how can we resolve these conflicts so that both parties have their goals met? Let’s look at three examples of common API design frontend/backend conflicts, then look for a way to resolve them.
Example conflict #1: Response payload formatting
Frontend developers often require the response payload to meet a specific structure to match the screen design. While it would seem straight forward to address the payload formatting requirements in the backend API, several situations may arise:
- The frontend visualization requires data aggregated in a specific way to reduce the coding effort required to build screen
- Teams are migrating existing screens to a new, API-centric architecture and don’t want to rework 10s to 100s of screens to match the new payload format
Watching teams argue about response payload formats is painful. Backend developers want to implement plain JSON, JSON API, HAL, Siren, Hydra, or other formats with the goal of longevity and interoperability. Frontend developers often want formats that make it easier to marshal/unmarshal the payloads for easy rendering. I have been asked to be the tie-breaker in these sorts of conflicts. The difficulty is that no one team is right or wrong – they both have needs that are equally important.
Hypermedia-driven payloads are especially interesting as the backend API may be designed for mobile consumption through the embedding of related resource summaries. This can lead to a secondary issue of the n+1 query problem as clients are forced to navigate hypermedia links for related resources. Let’s examine this conflict next.
Example conflict #2: Performance problems due to n+1 API calls
You have probably experienced database performance problems from n+1 queries before. The n+1 query problem occurs when applications perform an initial database query, then perform a new database query for each result of the first query. For a query that results in 100 results, the application makes 101 database calls. That is not the most performant way to build a web application.
While the database n+1 query can impact our web application performance by a few hundred milliseconds or so, the impact on APIs is considerably higher due to the addition of network latency. Additionally, there is often considerable work for the API consumer to write the client code to fetch the initial API response, then perform tens to hundreds of follow-up API calls to fetch the additional data and build the necessary data structures to drive a single web or mobile screen.
Key indicators that n+1 API calls is an issue:
- The target device has limited network bandwidth and requires additional data to be available that isn’t supplied by the backend API
- Developers designed response payloads without summary details for related resources, forcing the API client consumer to resolve the issue themselves
Unlike example #1 above, the impact of this issue is not limited to what the frontend developer. Instead, performance issues can be exposed to the customer, resulting in a poor user experience and customer churn.
Example conflict #3: Database-centric API design
When teams say that they are using REST for their API, it can pretty much mean anything. From RPC-style APIs, to those building hypermedia REST and everything in between – API designs can have a variety of different approaches.
One popular approach is to wrap your database with an API. I don’t recommend this approach, as web-based resources often need to represent a more course-grained view of your system and include workflow affordances for the client.
However, there are times when taking this approach just makes sense or is necessary to meet particular business need. I wrote an article about this some time ago, where I outlined the steps to take if you really need to take this approach – including how to design a better API in the process. However, a straight CRUD-over-database approach does bring its own kind of conflicts:
- Tight-coupling to database schema, resulting in a change to the API payload field names when a column is renamed or removed
- Lack of higher-level workflow endpoints, forcing multiple API calls to be made to accomplish a goal (similiar to the n+1 issue above)
From my experience, this seems to be the most common as APIs are often designed bottom-up from an existing database. Frontend teams must then struggle to map a solution-centric user interface to a storage-centric API design. However, backend developers tend to be unwilling or unable to make the appropriate changes to optimize the API calls required to accomplish the task at hand.
Conflict resolution through layered API design
The hope is that our integration between API clients and server will look like the following:
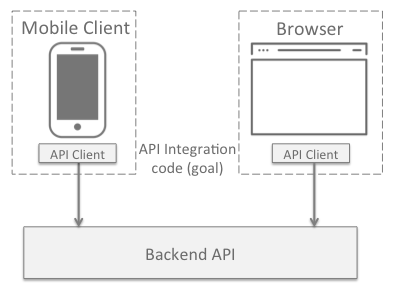
As you may have noticed, this isn’t always the case. Instead, a few issues may arise that are at the root of this conflict:
- The frontend team want to reduce the burden of coding by requiring that payloads fit the UI design and limit API calls where appropriate
- Backend developers want to optimize the endpoints for both reuse and rapid development
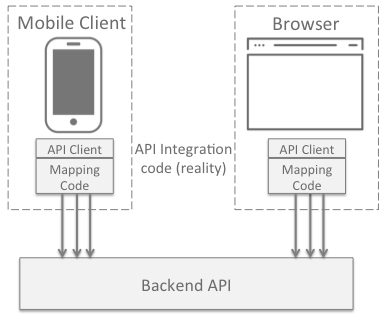
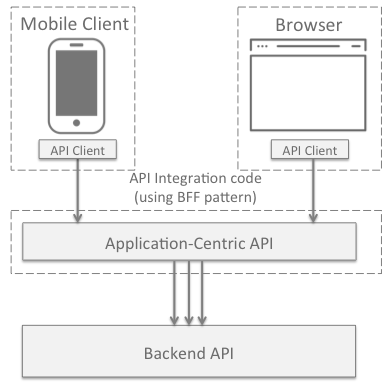
To resolve this conflict, we need to find a way to support both parties. A common approach to doing this is by using layered API design. Within the microservices space, this is commonly known as the Backend For Frontend (BFF) pattern.
The BFF pattern allows the backend API to remain as-is, with a new API constructed and consumed by frontend developers to meet the needs of the UI. There are two primary approaches to use the BFF pattern:
The Application-centered Approach:
- Driven by use cases by the end user, often workflow related
- Traditional backend APIs are viewed as smaller composable endpoints
- Use cases are realized by combining these smaller composable endpoints into new APIs
- This is similar to traditional SOA or microservices
The Device-centered Approach:
- Driven by the device functionality (e.g. mobile app, web)
- Encourages the repeating of code across device APIs, adapting payloads and even behavior as necessary
- Supports reducing roundtrips for mobile applications that have to handle unreliable networks
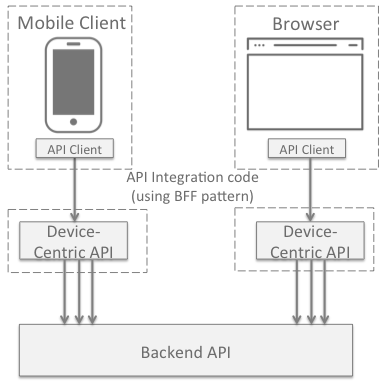
Both approaches support the idea of pushing the orchestration closer to the server tier where the backend APIs resides and network latency is lower. This reduces client network traffic to just one or two API calls to the BFF API, which can be significant for mobile applications.
Use caution applying the Backend For Frontend (BFF) pattern
The Backend For Frontend API design pattern is a useful tool for teams to resolve conflict and ensure that APIs solve real world problems. One major downside is that this creates yet another API that needs to be maintained over the life of the application. For larger organizations, this may not be an issue; however, smaller teams may struggle to keep up with the changes to the backend API and one or more frontend APIs.
Another hazard is that these layered APIs are not treated as well as the “flagship” platform API. At best, lapses in security, documentation, testing, and design will creep into these APIs, exposing the product to a variety of issues. Worst case, personally identifiable information (PII) may be released without proper authorization, or industry/government regulations may be compromised.
Don’t take shortcuts when building device or application-centered APIs to address these conflicts. Treat them as API products themselves.